Building Bitcask in Go: Architecture, Concurrency and Benchmarks
I want to build a simple database in Go and learn as much as I can from the experience. I’ve chosen to implement the Bitcask architecture, a simple write-oriented design. Repo
Architecture Link to heading
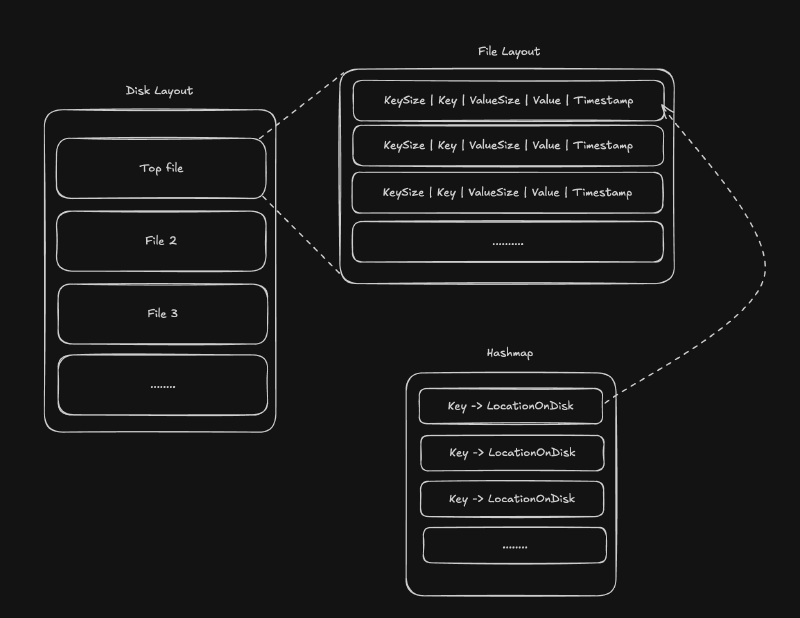
Bitcask as an architecture is fundamentally about maintaining a set of open “log files”. Every single write appends to the most recent log file. Additionally, a hashmap is maintained in memory which maps a given key to a location of the most recent version of the value based on these files. Multiple files are used for this purpose as opposed to one for the following step: periodically, Bitcask will iterate over previous files and merge them together, eliminating duplicate values and saving on space.
This architecture allows for extremely fast writes (every write points to exactly one spot in memory, the very end of the current write-to file) while preserving read speed. The tradeoff is that the system has to balance when and how to clean up duplicates, as those duplicates can temporarily cause high memory usage.
Concurrency model Link to heading
I took extra care to focus on concurrency for this project. In building high performance systems, it is crucial to follow strict principles such as locking shared resources, using queues and using Go’s built-in primitives such as select statements, to organize the path of execution.
In my implementation, there are 2 core domains where resource contention is possible. Firstly, two operations, notably a write and a read, could try to read from the topmost file at the same time. Two reads from any other file are not a problem since they don’t interfere with each other and writes only happen at the very top file. Hence, Go’s RWMutex (read-write mutex) comes extremely handy, allowing me to make this distinction easily. Every opened file object is directly tied to such a mutex via the segment struct.
Secondly, the main hashmap (key to EntryLocation) could be contended for, both by reads, writes and merges. Therefore, access to this map is locked behind another RWMutex. The get() showcases the logic behind this clearly: the lock for the map has to be acquired, and only then can the file header for that entry’s location be opened. Then the file lock has to be acquired. After which the map lock is released as this thread continues to execute on the file read. This illustrates the two layers of locks necessary for every operation.
The merge step is by far the most complicated step due to the amount of steps it has to perform. Merge has to perform the following steps: 1. lock the entire hashmap for both reading and writing 2. iterate over every entry in it 3. fetch the value from the previous files 4. write them to new temporary files and update in a new hashmap and lastly 5. switch the old hashmap with the new hashmap and old file pointers to new file pointers, thereby completing the rotation. The bottleneck here is that merge needs the full read-write lock on the hashmap which means writes are impossible for the duration of the merge.
Code example Link to heading
get function
|
|
This code snippet above illustrates the two-domain lock system. To retrieve a value based on a key, stateMu is locked until the correct file is found. Once the file is found, its own lock (fileLock) is acquired and only then is stateMu released.
Testing Link to heading
Testing to make sure there are no race conditions and deadlocks in such a system is absolutely essential. These tests concurrently stress the DB under disjoint keys vs shared keys, with SET/GET checks per iteration and a final verification in the shared-key case; full race detection is via go test -race.
Besides performing regular unit tests on individual functions, I’ve added two tests to specifically test the concurrency model: TestConcurrentDisjoint and TestConcurrentSharedKeys. Both of these tests create a temporary db instance, and spawn a number of goroutines. Each routine sets a number of fake keys (following a pattern). The key here is that these goroutines are run concurrently, thereby testing the DB’s ability to process them. TestConcurrentDisjoint tests the DB’s ability to write keys (every key is unique) and fails if a write fails while TestConcurrentSharedKeys tests the ability to write and overwrite keys. Keys are generated before the concurrent step, each goroutine overwrites the key multiple times, and at the end, the results in the db are verified to ensure everything matches up. This testing strategy is absolutely crucial in guaranteeing that the system is able to handle a real workload.
Benchmarking Link to heading
I’ve elected to use two different avenues to measure the performance of this app. The easy and straightforward way is to write microbenchmarks directly in the codebase, testing individual operations (get, set, sequential and concurrent) with Go’s built-in testing.B infrastructure. The second method involves using memtier_benchmark which simulates a real workload over multiple threads and connections. I benchmarked my app against a real in-memory Redis instance. While these are different architectures, I thought it would be fun to compare.
The benchmark setup was:
- Bitcask running on localhost:8080 versus a Redis docker container running locally
- 128 byte values, 4 threads, 50 clients.
Results:
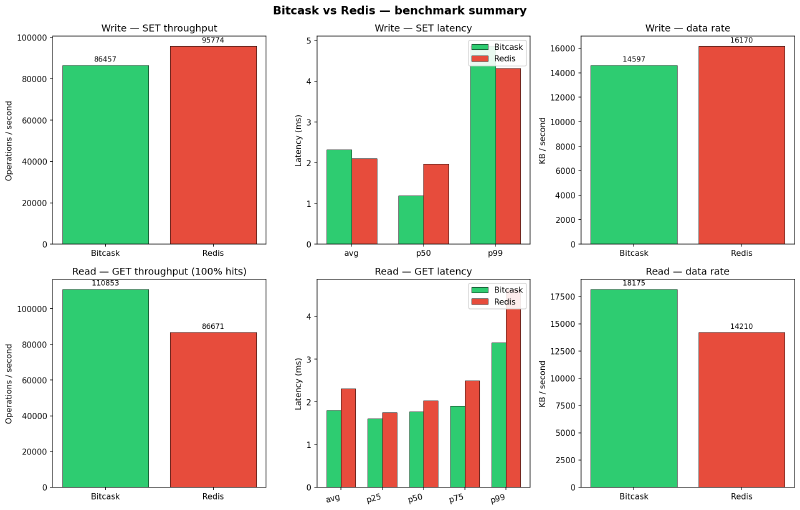
Overall, I am happy with the performance of my Bitcask implementation. While it supports significantly fewer features than real Redis, it doesn’t run in memory, but on disk and despite this, I get faster reads with lower latencies, while being very competitive on writes.
Room for improvement Link to heading
I have many ideas as to how to improve performance further:
- get only reads the bytes that contain the value from the disk, no need to return the entire entry and then decode it. Saves on some redundancy.
- have multiple “head” files to which we write. This would allow for parallel writes at the cost of significant complexity at the merge level and at the write level since now Bitcask will need some sort of a consistent hashing scheme.
- buffered writers that buffer incoming writes at the application level and batch write them to the disk at once. This should make writes even faster at the cost of potentially losing unwritten data in the case of a crash.
- change the merge step to be as unobtrusive as possible. Something like immediately start a new write file, freeze the old ones as immutable, and in parallel, write to the new file while compacting the old files.